The issue is that I didn't make the workflow, and have a limited understanding of the material for right now. I was running into an error saying mat 1 and mat 2 cannot be merged; this is merging the 2 input streaming that stable would reinterpret. The issue was solved by removing the connections to the CNET nodes. This leads me to think that my CNET models are for 1.5 and not XL, which is (i think) how this workflow is set up. I'll try again later today and post the results.
I think people are taking the wrong approach to AI video. You can see that in every frame the images are very distinct. Everyone wants to adapt 2D AI to video. But I think the right way to do it is to perform diffusion on a 3D tensor.
Of course then resolution becomes an issue. Maybe the answer is gaussian splatting considering that is already working effectively in 3D. That or maybe techniques could be used like in upscaled MiDaS where you zoom into different levels and reprocesses.
But if we did diffusion in 3D to make video you could get some pretty trippy videos where backwards and forwards are symmetric and you could get some backwards stuff and forwards stuff in the same frame. Or you could have symmetries in the x and y dimensions with time and that might be cool.
Hopefully it can learn that things like to have arching shape in time, parabolic motion, feet stepping off the ground and back on, but that the spacial dimensions aren't quite as archy.
I ran some experimentation about a month or 2 ago on using panoramic video output by maya and then reinterpretation of that footage by stable and that gave some interesting results. Using panoramic as a prompt will kick out 360 video stills, and injecting that with 360 meta does make a VR video - however, issues with the "position" of the "camera" that i could not figure out. Temporal Diffusion models are attempting to address the continuity issue that comes with VAE interpretation of noise. At least i THINK i know what i am talking about. Loopback gave good results as its blends the prior frame with the current output, but that leads to ye ol' hindu gods (5 armed lobster woman). I think if one wants to solve continuity currently, then generate images (for web comics for example) of famous people should give the model thing to work from and then every frame you have your subject. I know very little python (i gather its mostly scriddies relying on libraries to do their work, nothing wrong with that though), and thus my understanding of the tensor flow model is limited. I am interested in implementing my own seq2seq for novel approach to LLM and GTP design, so i guess i gotta lot to read. Any suggestions on material to consume?
Maybe there could be something useful where we do sub-frame interpolation that is a little more creative than direct interpolation.
Give Frame 0; Give Frame 100; Give frame 50 from frame 1 and 100 with temperature 10; Give frame 25 from 1 and 50 with temperature 5; Give frame 75 from 50 and 100 with temperature 5; Give frame 12 from 1 and 25 with temperature 2.5;
IDK.
I want to see that 5 armed woman. Maybe in seeking perfection we lose the best art. Next we'll have hyper realist models and people will be banging their heads trying to get it to generate multi-armed people or abstract art more generally.
Separate reply because I realized I completely didn't read part of what you wrote so separate comment.
Interesting that you want to do some seq2seq. I'd love to hear about it. I've thought about that stuff a bit. Where I'm racking my brain on it is I understand how transformers work. I've even written some code to do it directly but haven't had a chance to test it yet. Where I'm at a loss is on the consumer side of transformers. Yeah, it seems like a great system to understand what someone wrote. Now how do you generate text from that? That's where I'm at a loss. If you have ideas about that end of things that could be quite useful.
For my own projects I'm likely to just modify llama so I guess I don't need to know that. But still your ideas might be useful if I ever wanted to start from scratch.
Let me know if you need to understand transformers. I'll give you a write up and link you to a few things.
That was very well done. Did you use Gradio or ComfyUI? Did you mask the still yourself and use the upload mask or did you use CNET and have it do it for you?
Nice, what was your custom node for the animator diffusor and what SD model did you use? My apologies for not checking your image for meta data, i'm busy shit posting.
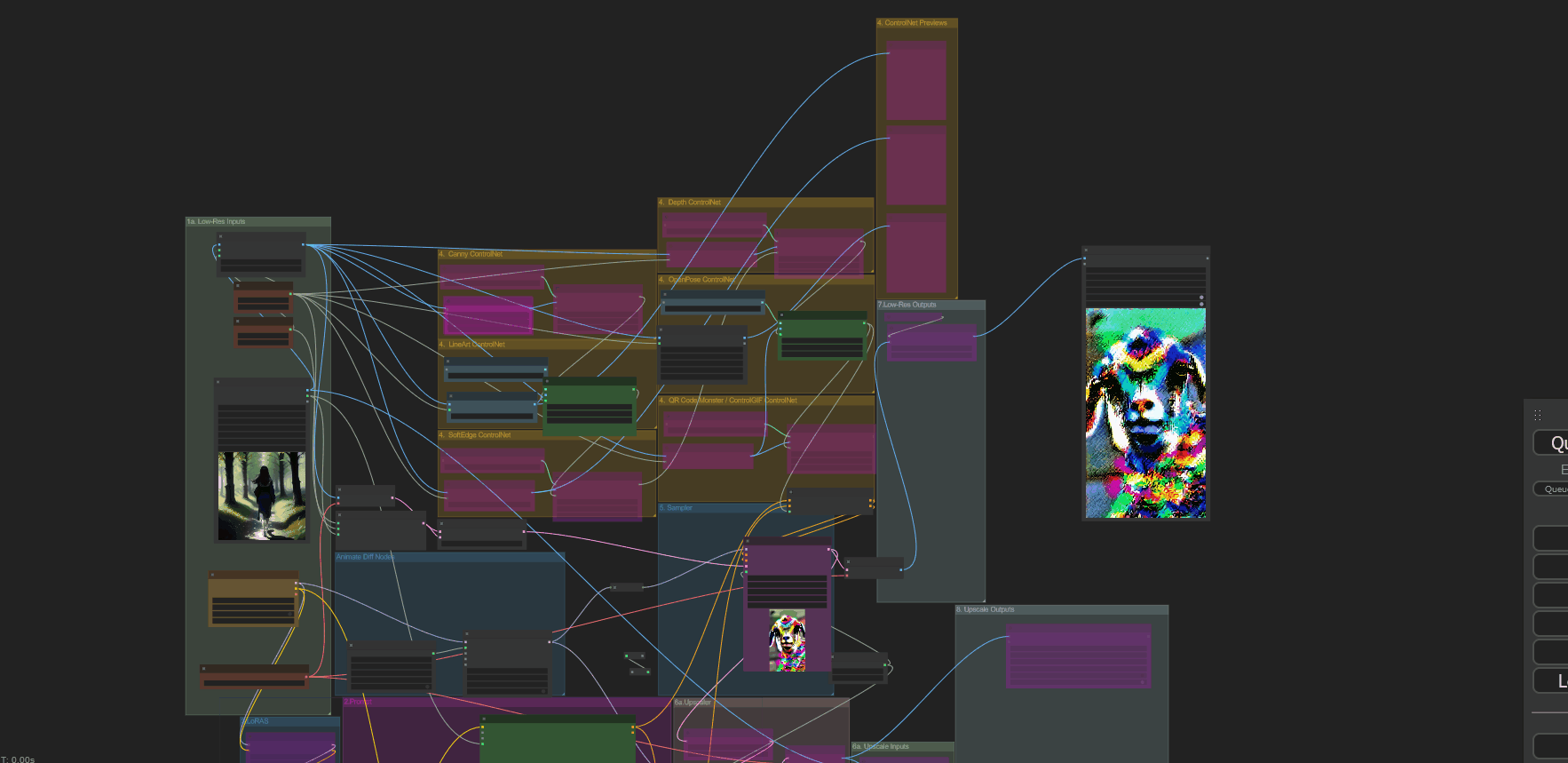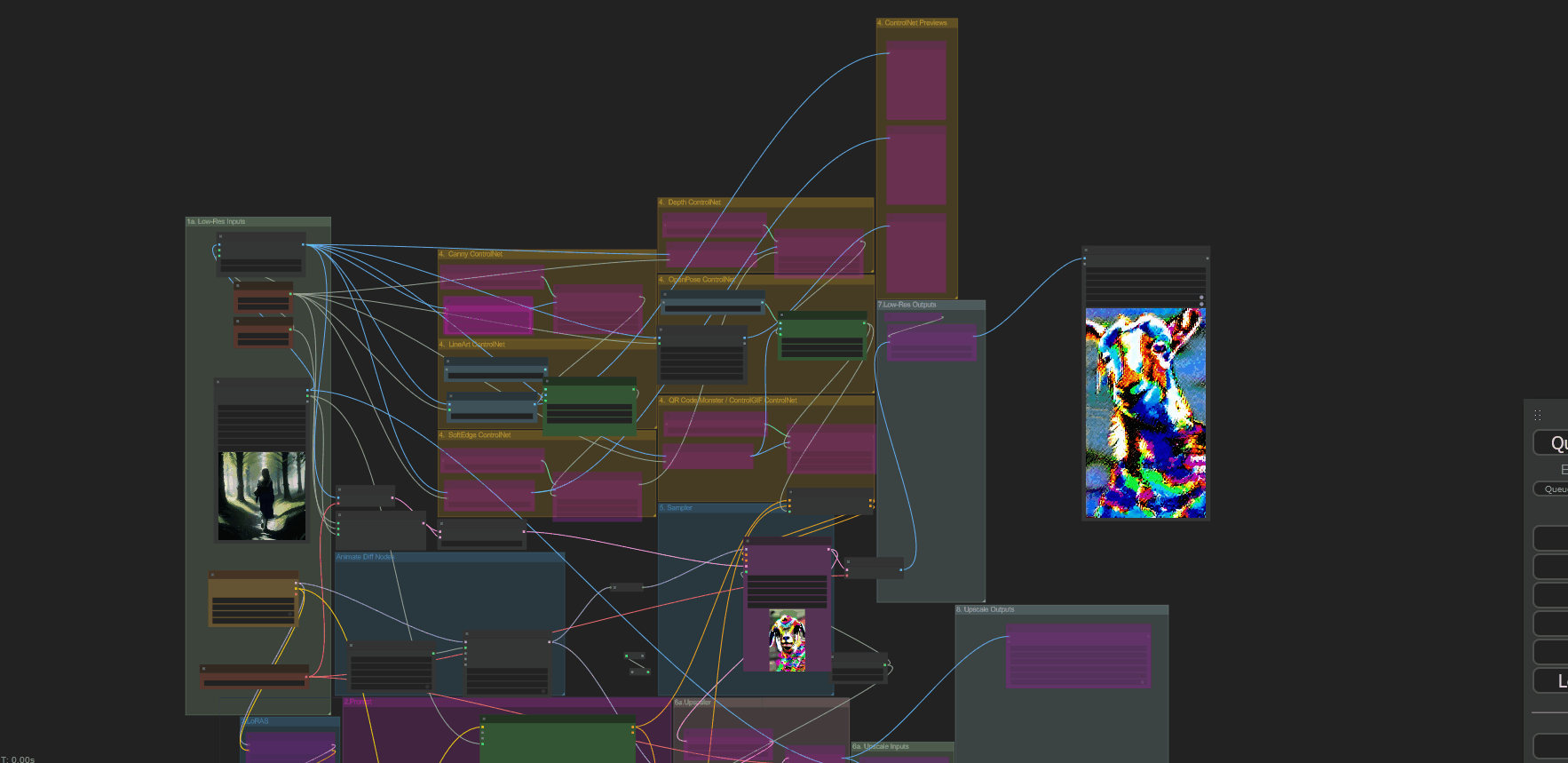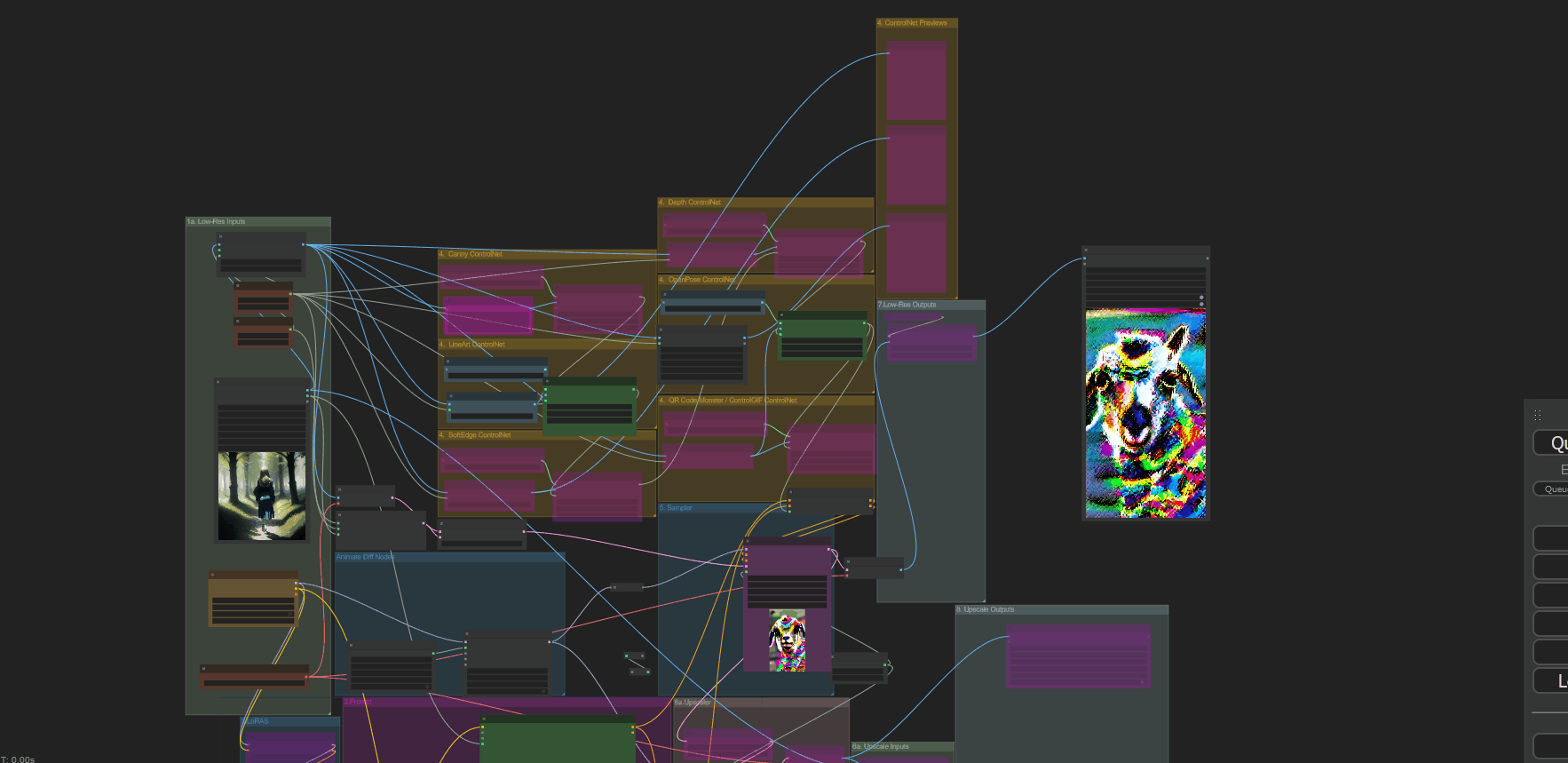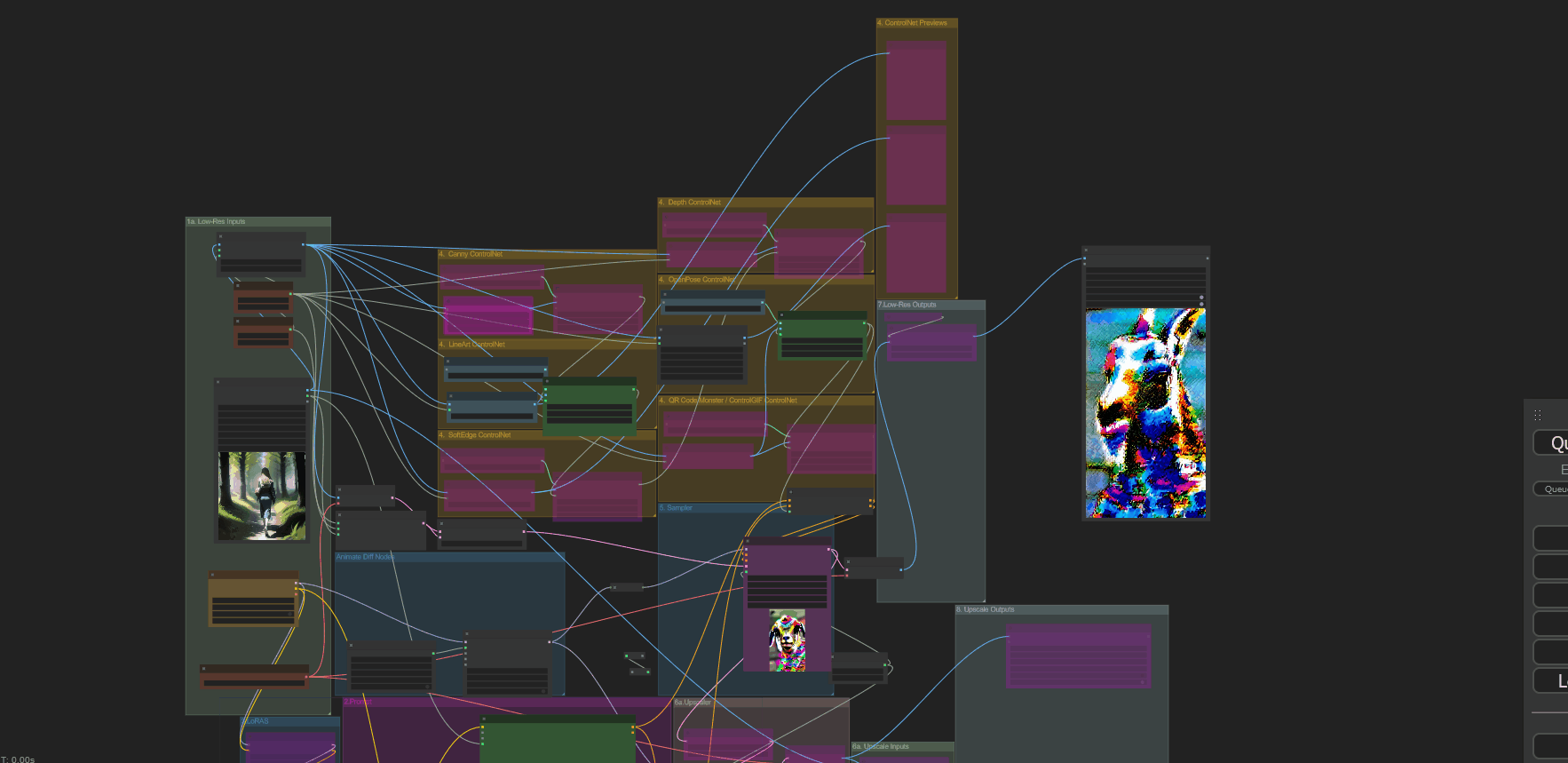
[ + ] Anus_Expander
[ - ] Anus_Expander 2 points 1.4 yearsJan 9, 2024 12:06:52 ago (+2/-0)
[ + ] symbolic
[ - ] symbolic [op] 1 point 1.4 yearsJan 9, 2024 12:37:48 ago (+1/-0)
[ + ] x0x7
[ - ] x0x7 2 points 1.4 yearsJan 9, 2024 11:28:44 ago (+2/-0)
Of course then resolution becomes an issue. Maybe the answer is gaussian splatting considering that is already working effectively in 3D. That or maybe techniques could be used like in upscaled MiDaS where you zoom into different levels and reprocesses.
But if we did diffusion in 3D to make video you could get some pretty trippy videos where backwards and forwards are symmetric and you could get some backwards stuff and forwards stuff in the same frame. Or you could have symmetries in the x and y dimensions with time and that might be cool.
Hopefully it can learn that things like to have arching shape in time, parabolic motion, feet stepping off the ground and back on, but that the spacial dimensions aren't quite as archy.
What software was that graph UI coded in?
[ + ] symbolic
[ - ] symbolic [op] 0 points 1.4 yearsJan 9, 2024 12:36:37 ago (+0/-0)
[ + ] x0x7
[ - ] x0x7 0 points 1.4 yearsJan 9, 2024 15:40:21 ago (+0/-0)*
Give Frame 0; Give Frame 100; Give frame 50 from frame 1 and 100 with temperature 10;
Give frame 25 from 1 and 50 with temperature 5;
Give frame 75 from 50 and 100 with temperature 5;
Give frame 12 from 1 and 25 with temperature 2.5;
IDK.
I want to see that 5 armed woman. Maybe in seeking perfection we lose the best art. Next we'll have hyper realist models and people will be banging their heads trying to get it to generate multi-armed people or abstract art more generally.
[ + ] x0x7
[ - ] x0x7 0 points 1.4 yearsJan 9, 2024 15:57:23 ago (+0/-0)
Interesting that you want to do some seq2seq. I'd love to hear about it. I've thought about that stuff a bit. Where I'm racking my brain on it is I understand how transformers work. I've even written some code to do it directly but haven't had a chance to test it yet. Where I'm at a loss is on the consumer side of transformers. Yeah, it seems like a great system to understand what someone wrote. Now how do you generate text from that? That's where I'm at a loss. If you have ideas about that end of things that could be quite useful.
For my own projects I'm likely to just modify llama so I guess I don't need to know that. But still your ideas might be useful if I ever wanted to start from scratch.
Let me know if you need to understand transformers. I'll give you a write up and link you to a few things.
[ + ] Deleted
[ - ] deleted 0 points 1.4 yearsJan 10, 2024 01:51:21 ago (+0/-0)
[ + ] Niggly_Puff
[ - ] Niggly_Puff 2 points 1.4 yearsJan 9, 2024 11:24:50 ago (+2/-0)
https://files.catbox.moe/y61xqr.webp
[ + ] symbolic
[ - ] symbolic [op] 0 points 1.4 yearsJan 9, 2024 12:39:54 ago (+0/-0)
[ + ] Niggly_Puff
[ - ] Niggly_Puff 1 point 1.4 yearsJan 9, 2024 13:15:09 ago (+1/-0)
[ + ] symbolic
[ - ] symbolic [op] 0 points 1.4 yearsJan 9, 2024 13:41:22 ago (+0/-0)
[ + ] Niggly_Puff
[ - ] Niggly_Puff 1 point 1.4 yearsJan 9, 2024 13:45:30 ago (+1/-0)
https://comfyanonymous.github.io/ComfyUI_examples/video/
One for txt to animation and another for img to animation. About 8 nodes or so, no idea what you had going on there lol
[ + ] symbolic
[ - ] symbolic [op] 0 points 1.4 yearsJan 9, 2024 13:53:47 ago (+0/-0)
[ + ] x0x7
[ - ] x0x7 0 points 1.4 yearsJan 9, 2024 13:01:05 ago (+0/-0)
[ + ] Niggly_Puff
[ - ] Niggly_Puff 0 points 1.4 yearsJan 9, 2024 13:14:38 ago (+0/-0)