First the new architecture
https://files.catbox.moe/1tygoo.png![]() https://files.catbox.moe/n308f1.png
https://files.catbox.moe/n308f1.png![]()
Working on cryptography and got one of the last major modules functioning.
Summary:
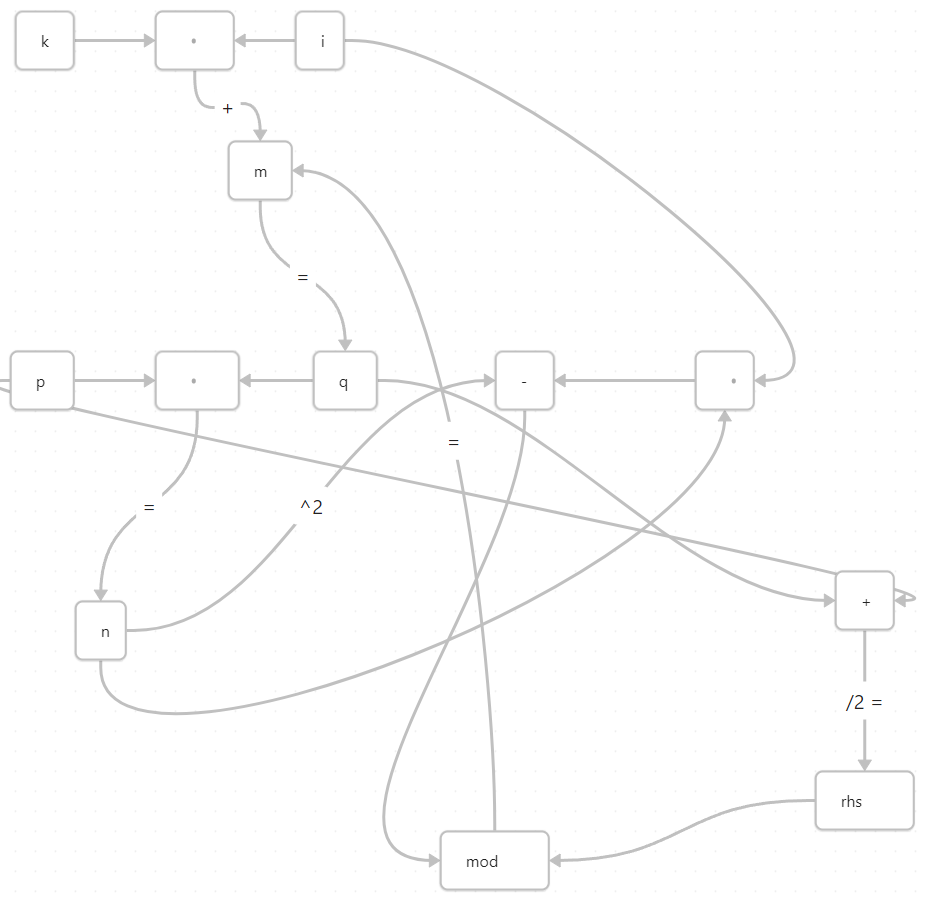
The central insight is that you can generate approximations of factors using variations on modular arithmetic that will be accurate to the leading digits of a semiprime's lowest factor. Then, by applying various constraints, you can dramatically reduce the search space.
The algorithm's efficiency comes from the fact that the modular set grows much more slowly than the bit length of the semiprime, making it vastly more scalable than traditional factorization methods.
This approach bridges number theory, machine learning, and optimization techniques in a novel way to solve the prime factorization problem.
code (partial)
https://pastebin.com/raw/DHADM0nWFull text:
What I'm doing is using the code listed here
to generate a list of possible values of A (where the problem is p=ab, or n=pq in cryptography), and then using the boundaries established with other variables from a separate module, called d4a, ac, at, av, etc
to start to eliminate values.
ML will be needed to classify whether unknowns are
inverted (abs(unknown) < 1).
While the number of values to consider grows, assuming we know
whether an unknown is inverted we can take known
variables & use them as upper (or lower) bounds on A,
filtering significant numbers of values.
More importantly, the number of values to check in the modular
set grows much more slowly then the bitlength of the semiprime
to check.
We'll call the set of equations (d4a, at, ac, av, etc) the Algebraic Set (AS).
The set of modular values derived from p (or n) we'll call the Modular Set (MS).
The algorithms I wrote in the 290+ set, we'll call the Convergent Set (CS).
The machine learning model that classifies whether unknowns are likely to be inverted or not (abs(n) < 1), we'll call the Configuration Set (FS).
And the code written to generate boundary estimates we'll call the threshold set (TS).
How and why it works.
I determined the AS is indeterminate (I've checked well over a billion solutions so far, and probably on the order of several thousand novel methods to attack the problem, variations of it, and simplified versions as well, in the domains of algebra and the minimal calculus that I know), that is there is insufficient free parameters to map between the known and unknown set, and thus factor our product.
The modular set is derived from certain equations relating the various magnitudes to themselves. The MS guarantees that for some vector of values [p, u, k, i, j] some of which are trivial to estimate, there will within the set generated, always be a value that approximates A in P=AB, up to the leading 1-2 digits (and often more) and magnitude.
By taking the AS we can use the FS to derive boundaries, giving us the TS.
With the MS, we can use the TS, to efficiently derive estimates of all unknowns that have factors in common, such as and including (but not limited to) u (unknown) from d4u, ut, cu, and uv (all known).
With these estimates, we can then feed them to the CS to essentially strip away multiple outer and inner loops of the algorithm, giving us significant orders-of-magnitude improvements in convergence time.
This is one of the final pieces of the puzzle.
Current risks are:
- if the ML component can correctly identify if unknown variables in known products and quotients are inverted or not.
Preliminary testing with smaller model and datasets (<100k samples across various bitlengths) indicates this will work.
- re-groking the later basilisks which are incredibly convoluted and have to have parameter sweeps for tuning done.
- gains vanishing at very high bitlengths owing to having to convert very large numbers to logarithms, and the ML model potentially failing because of that.
Mitigations:
- Larger sample-size testing for the ML model in order to establish the threshold set's definitive viability, rather than ad-hoc testing.
- writing clear documentation and procedures on the convergent set algorithm, so I don't have to work through it every time I want to implement something related to it
- writing my current off-the-shelf neural-graph-search (NGS) library from the ground up to accept arbitrary precision floats and integers
Obstacles:
- I'm not currently versed enough in ML to rewrite the NGS, and no known library currently accepts arbitrary precision types. Most rely on numpy, and even numpys largest type support won't handle data in the 2-4k bits length.
Current delivery estimate:
"Two more weeks", or "Fuck you!"

{kind=link}
{kind=link}
{kind=link}